欧宝app(中国) 商汤SenseNova U1深度拆解, 原生结伙架构完结缝合时间


剪辑|杜伟
当 AI 行业的眼神聚拢在 Agent、用具调用、长程任务这些表层应用之时,底层的多模态架构正在资格一次更欣然、也更透顶的范式转变 —— 它要修起的是一个看似朴素的问题:纠合与生成,是否天生就该是两件事?
持久以来,多模态系统大都是拼起来的 —— 感知与纠合、生成各自承担一部分智商,再把它们串起来跑。问题也很明显:纠合通过预熟习视觉编码器(VE)竣事,生成依赖变分自编码器(VAE),两套系统的学习办法不同、暗示空间各别,信息在不同模块之间往复传递,未免出现损耗、走样。这不仅仅工程上的粗劣,更是一种结构性铁心,抵制了真确原生多模态智能的形成。
最近的一系列职责开释出了全新的信号,不执着「将系统拼的更好」,转而从底层脱手,把图像、文本、视频以致动作放进合并个暗示空间去学习和对王人。商汤科技开源的新一代模子「日日新 SenseNova U1」恰是这一方朝上的聚拢实践。
上个月,Google DeepMind 用一个通用模子 Vision Banana,解释了「生成即纠合」。SenseNova U1 基于行业始创的 NEO-Unify 原生结伙架构,让多模态纠合、推理与生成在模子里面形成一条好意思满的链路,而非依靠外部模块拼接。
这次开源的轻量版 SenseNova U1 Lite 系列包含两个不同规格的模子:基于宽绰骨干汇聚的 SenseNova-U1-8B-MoT 和基于 MoE 骨干汇聚的 SenseNova-U1-A3B-MoT(总参数 38B,纠合生成激活参数各 3B)。
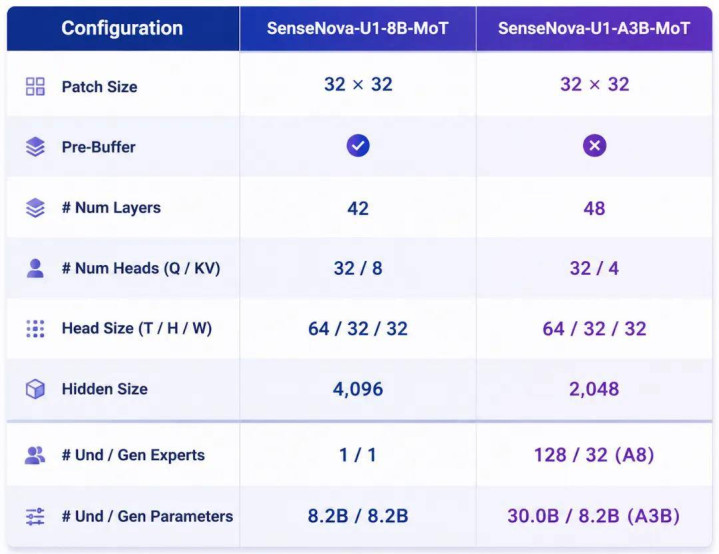
模子规格概览
模子在 Hugging Face 与 GitHub 开源后,在外洋建造者社区飞速激发磋议。在 X、Reddit 等平台,「实足去掉 VE 和 VAE 的结伙架构」被视为近期多模态领域最值得关爱的工程实践之一;建造者尤其关爱其在 8B 领域下能挑战更大交易闭源模子的图文生成与剪辑智商,以及实足开源(含代码、权重、工夫敷陈)的政策遴荐。
就在日前,商汤科技放出了好意思满的工夫敷陈:

工夫敷陈:https://arxiv.org/abs/2605.12500
模子下载:https://huggingface.co/collections/sensenova/sensenova-u1
GitHub 代码仓库:https://github.com/OpenSenseNova/SenseNova-U1
回来第一性旨趣
多模态从拼接走向耦合
谈话与视觉并非异质信号,而是对合并现实寰球的不同编码 —— 这是 NEO-Unify 的起点,亦然商汤科技在假想 SenseNova U1 时所回来的底层原则。
基于这一旨趣,NEO-Unify 让模子径直从接近原始形态的信息(像素与笔墨本人)中学习,在学习过程中形成结伙的里面暗示。纠合与生成不再被绝交处理,而在合并体系中结伙建模。
下图为 SenseNova U1 模子及 NEO-Unify 架构概览:
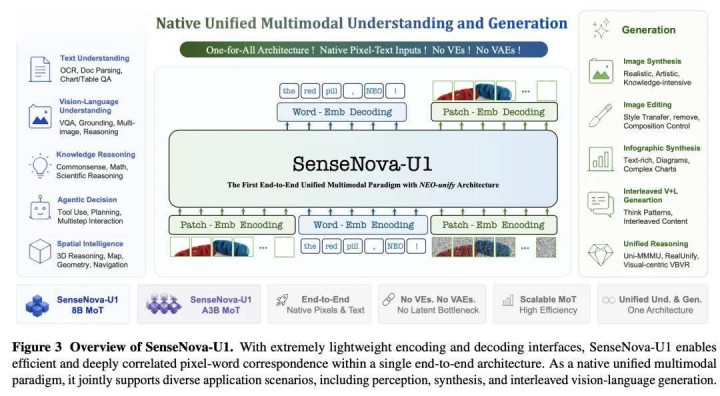
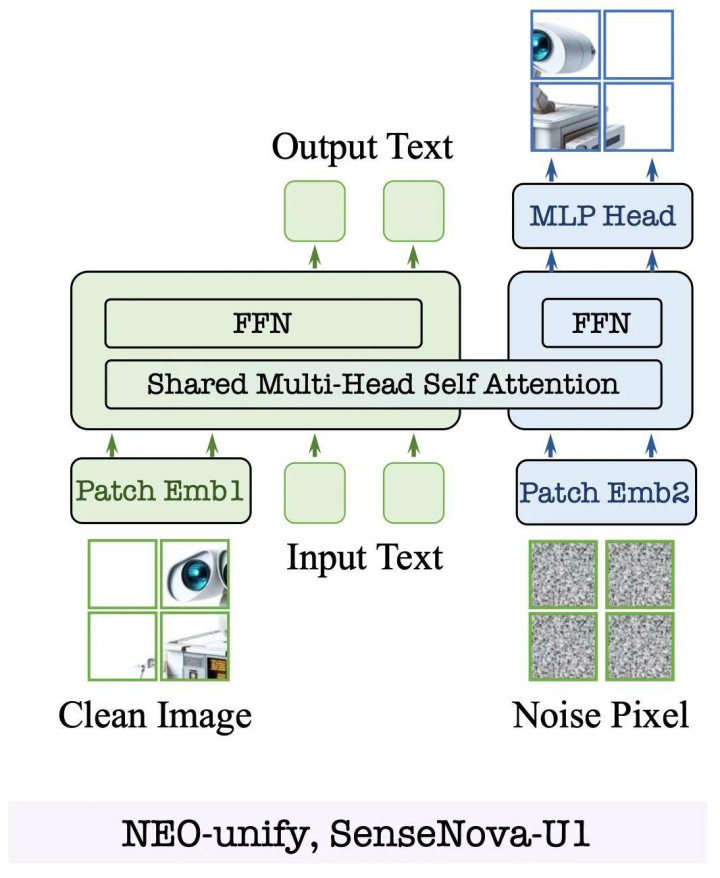
为了竣事这一办法,NEO-Unify 需要同期治理以下三组主要矛盾,三者呈递进联系:从输入输出接口层的暗示结伙,到熟习知道性的保险,再到纠合与生成参数层的协同。
矛盾一(接口层):排斥模块割裂,打造近无损视觉接口。
传统模子依赖预熟习的视觉编码器(如 CLIP)或解码器(如 VAE),这是语义纠合与像素生成之间存在自然暗示鸿沟的根源。NEO-Unify 收受了 Encoder-free 假想:输入端排除预熟习 VE,改用两层卷积加 GELU 激活将图像鬈曲为 token(每个 token 对应 32×32 像素块);输出端视似排除 VAE 解码器,径直用 MLP 计算原始像素块。
这种反传统假想让模子领有了在「结伙暗示空间」自主学习的智商 —— 在提真金不怕火高层语义进行纠合的同期,精确保留局部纹理和笔墨角落以供生成。工夫敷陈中的消融实考据实了这少许:NEO-unify(2B)在 MS COCO 2017 上的图像重建 PSNR 达 31.56、SSIM 达 0.85,接近 Flux VAE 的 32.65 和 0.91,证明近无损输入既能营救语义纠合,也能保管像素级精度,无需依赖任何预熟习编码器。
矛盾二(熟习层):治理动态分辨率的信噪比失衡,竣事生成知道性。
在多模态纠合与生成的结伙架构中,模子需要处理从 256×256 到 2048×2048 的大跨度动态分辨率。传统扩散模子或 Flow Matching 时时基于固定噪声先验,当分辨率变化剧烈时,像素点数目级差异会导致模子在不同范例下信噪比(SNR)不一致 —— 高分辨率下易结构崩坏或过迷漫,低分辨率下可能丢失细节。
NEO-Unify 的解法是引入分辨率自适合噪声范例:分辨率越高,生成的 token 数越多,噪声标准差就按平日根比例同步上调,从而使每个 token 在不同范例下承受约莫辩论的噪声能量,保证 Flow Matching 过程中 SNR 散布的一致性。与此同期,这一自适合范例被编码后行为条款引入去噪器,让模子在濒临不同分辨率输入时永恒保持一致的推理视角。
两者联结,保证模子在千般分辨率下生成愈加知道,幸免范例切换带来的熟习不治理和输出伪影。
矛盾三(参数层):以原生 MoT 架构竣事「知识分享、专才专用」。
理罢黜务需要从图像中索要语义,生成任务需要将语义鬈曲为像素 —— 二者办法不同,径直分享系数参数会产生梯度侵犯。NEO-Unify 引入原生 Mixture-of-Transformers(MoT)架构:纠合流与生成流在底层分享自精明光高下文,但在具体的 Q/K/V/O 投影、归一化及 MLP 层进行实足参数解耦,每层把柄 token 类型动态路由。
这竣事了「知识分享、专才专用」—— 纠合与生成从互不干与走向协同鼓舞,工夫敷陈的消融实验闪现,两种智商在 MoT 骨干中协同演化,本体冲突极小。
此外,为让一维谈话序列与二维图像结构在合并个 Transformer 架构下共存,NEO-Unify 引入了三维 RoPE 旋转位置编码(T/H/W 三轴各有沉静频率基),从底层对王人谈话顺次和空间结构;收受搀和精明光(Mask)模式,文本 token 走标准因果精明光,同块图像 token 之间双向关爱并保持对前置高下文的因果条款 —— 这在保证谈话生成的逻辑连贯性,餍足了图像块之间空间一致性的需求。
通过一系列架构上的篡改,SenseNova U1 告诉行业:真确的多模态智能不应仅仅给谈话模子安上眼睛,要让模子从降生的第一天起,就用合并套感官去理解和创造寰球。
数据、训推三位一体
打造原生结伙引擎
架构上的篡改组成了 SenseNova U1 的假想中枢,而数据、熟习与推理的深度协同维持起了模子的高效运行。
熟习数据:超 3.4 万亿 token 的全感官语料
SenseNova U1 在数据层面号称「全感官大脑」。其中预熟习语料约 2.1 万亿 token—— 在同类开源结伙模子中属顶量级 —— 涵盖图文对、图注、信息图纠合和纯文本,开首经过跨源去重、内容安全过滤、图像质料过滤和 CLIP 比率均衡重标注等。
立博体育LIBO中国官网中期熟习阶段收受里面 SenseNova V6.5 数据集,掩饰通用、Agent 与空间、知识推理和纯文本四大类,并通过三阶段筹办管谈确保质料:基于 CLIP 的千般性采样→指示增强(从语义抒发、情势治理、脚色场景、任务复杂度四维推广)→多标准质料筛选(正确性、幻觉检测、指示实施三维评估)。
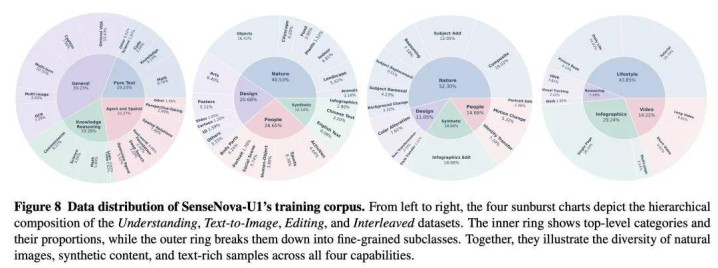
SFT 阶段进行了高强度指示微调熟习,数据掩饰空间智能、多模态纠合、推理等十个垂直领域。在纠合预热、生成预熟习、中期熟习与 SFT 四个熟习阶段中,模子累计 token 数卓绝 3.4 万亿。
在生成和交错数据侧,语料涵盖视频、生涯情势、信息图和推理四类,确保用视觉意见掩饰的同期强化了东谈主物身份等一致性。一套「隐式 prompt→ 推理过程 → 显式视觉 prompt」熟习过程, 将玄虚学问和逻辑鬈曲为可考据的画面。丰富数据的引入,让模子在处理相应任务时诓骗自如。
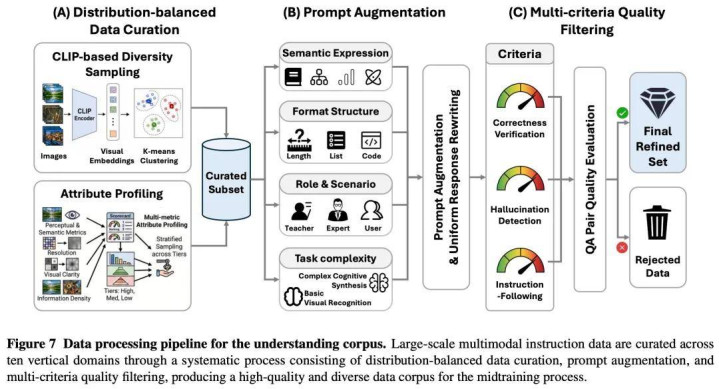
熟习过程:「先稳态、再耦合、再对王人、后加快」四步走
SenseNova U1 放弃了传统意旨上的多任务搀和,采用「渐进式智商演进」政策,通过一套「先稳态、再耦合、再对王人、后加快」的智商栈,治理了大领域原生结伙模子在多模态协同中的不知道性。
第一步,纠合预热(Warmup):基于预熟习 NEO 纠合模子进行精明光会通与全模子连续熟习,将 NEO 平分离的文本和图像 QK 投影整合为结伙分享布局,还原精明光后果,构建 SenseNova U1 的语义骨干。
第二步,生成预熟习:冻结纠合分支、专攻生身分支,让模子在 256 到 2048 的动态分辨率下掌执知道的图像生成与剪辑智商。
第三步,结伙中期熟习:两个分支同期激活,在纠合、生成及图文交错搀和下端到端结伙熟习 84k 步,欧宝app官方版竣事模态间的深度耦合。
第四步,结伙 SFT:在高质料指示实施数据上微调 9k 步,强化指示扈从智商,确保模子精真的施复杂多模态任务。
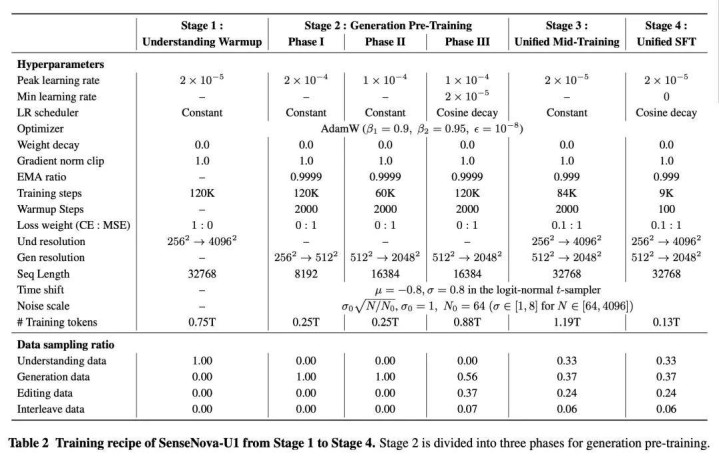
熟习终局引入后期熟习(Post-training):利用 Flow-GRPO 机制,分两阶段进行强化学习。
此外,利用矫正的散布疋配蒸馏(DMD2)工夫将生成步数从约 100 步蒸馏到 8 步,在保证生成质料的前提下,大幅进取从实验室模子到工业级落地的鸿沟。
推理系统:解耦部署,FlashAttention3 后端高蒙胧
可以将 SenseNova U1 的推理系统想象成一个「复合大脑」,在对外保持结伙接口的同期,对内竣事了 LightLLM(注意多模态纠合、文本流式输出和肯求诊治)与 LightX2V(注意图像生成)的深度解耦。
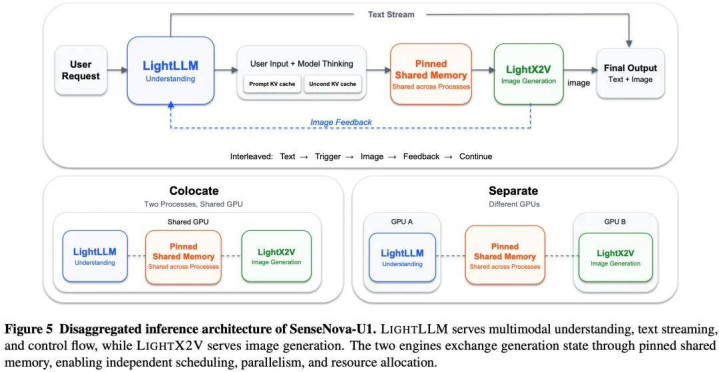
这两个引擎通过锁页分享内存和优化输出内核来高效交换景况。解耦假想带来三方面实用上风:第一,允许纠合引擎使用面向大模子的张量并行(TP),生成引擎则收受 CFG 并行或序列并行;第二,营救沉静资源分拨,包括分开的 GPU 组、内存预算和批处理政策;第三,使文本密集型和图像密集型流量粗略沉静推广、分析与调优。
在过错优化上,该系统用到了搀和精明光机制:纯文本部分走标准的因果 fast path,仅在处理包含图像 token 的块时才动态推广 key range,按需分拨筹划量,大幅裁汰推理冗余支拨。加上 FlashAttention3 后端的加快,在结伙多模态 Prefill 阶段比传统 Triton 有策画快。关于 2048×2048 图像生成,在 5090 和 L40S GPU 上的每步蔓延分辩是 0.415 秒和 0.443 秒。这意味着,底层算子得到了进一循序优,复杂的推理和生成在履行部署中跑得很顺。
系数这个词看下来,SenseNova U1 在数据、熟习与推理的深度协同中完成了一次工业级底层范式的「蜕变」:海量知识经过四阶智商栈精确鬈曲为跨模态纠合与生成智商,并依托算子级优化与解耦的推理系统,打形成高效适配各样商用场景的 AI 坐蓐力用具。
全维度试真金不怕火场
开源小模子新顶流来了
为考据原生结伙架构 NEO-Unify 的成色, SenseNova U1 在掩饰纠合、生成、剪辑、交错和智能体的任务上进行了全场所测试。扫尾可归纳为三个档次:中枢突破性成绩、智商无损解释,以及交错 / 协同等推广智商。
在拆解工夫细节之前,先看一个能直不雅感受 SenseNova U1 智商的案例。
模子先纠合「双城记」「生涯反差」的 PPT 主题,在恰当逻辑与一致性基础上,进行笔墨与对应画面的一语气输出。这背后是结伙架构带来的「看懂 — 推理 — 生成」的好意思满链路。同期画面中汉文笔墨密集、版式分区明晰、配图与图标好意思满。笔墨可以位、不糊字,这是畴昔图像生成模子持久跨不外去的痛点。

这正好对应了接下来的评测数据。
中枢突破:纠合智商不因结伙而退化,反超更大领域模子
在行业传统理解中,将生成智商整合进模子可能会因占用参数容量而导致纠合智商着落。SenseNova U1 的实战证实龙套了这一担忧。
在 MMMU、MMMU-Pro 和 MathVision 等高难度专科推理基准上,A3B-MoT 成绩分辩达到 80.55、72.83 和 79.63,在 MMMU 上超越了 Qwen 3.5-9B 整整 2.15 分,在 MMMU-Pro 上以 2.73 分的上风最初。在空间智能(VSI-Bench:56.9、ViewSpatial:58.52、MindCube-Tiny:70.86)上相似显赫最初 Qwen 3-VL-30B-A3B 和 Gemma 4-26B-A4B 等同体量的模子。
收货于像素级建模智商,模子对细微笔墨和复杂布局有了更强的把执,在文本密集图像和结构化视觉信息任务上也莫得因结伙架构而出现智商退化:OCRBench 达 91.90 分、OCRBench-v2 达 68.64 分、MMBench-EN 达 91.59 分,均卓绝多个更大领域的竞品。
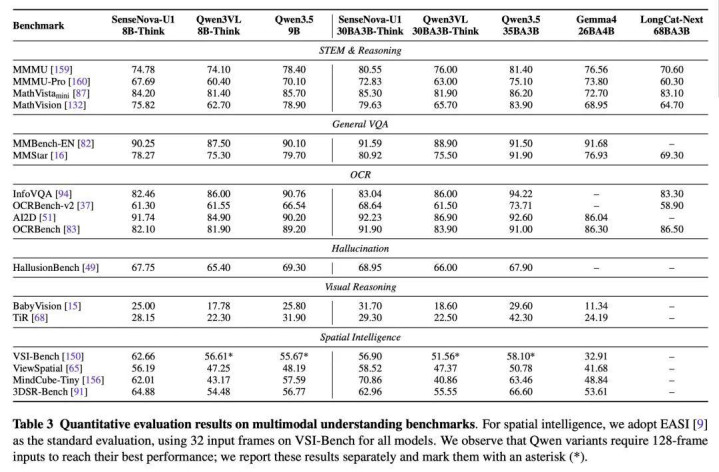
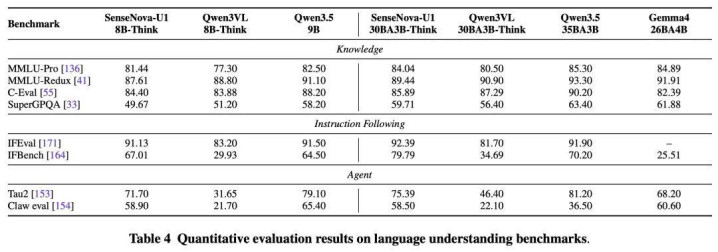
结伙范式也莫得焚烧谈话智商。在 MMLU-Pro(84.04)、IFEval(92.39)和 IFBench(79.79)等谈话纠合与指示实施基准上,A3B-MoT 均处于开源最初水平 —— 尤其是 IFBench 比 Qwen 3.5 - 9B 高出 15.29 分。在 τ²-bench 评测中,总分得分 75.39, 解释其具备可以的长程交互与用具调用智商。
智商无损解释:生成任务相似跑出 SOTA 成绩
既然纠合智商未受消弱,生成侧的证实更令东谈主期待。扫尾相似莫得令咱们失望。
在通用生成基准 GenEval 上,两款模子均以 0.91 的总分领跑开源阵营(Qwen-Image 为 0.87、BAGEL 为 0.82);在 DPG-Bench 上,A3B-MoT 以 88.14 分参加顶尖开源模子行列,Global 分数更以 94.19 名次系数对比模子第一,体现了在复杂指示下重大的全局语义有策画智商。
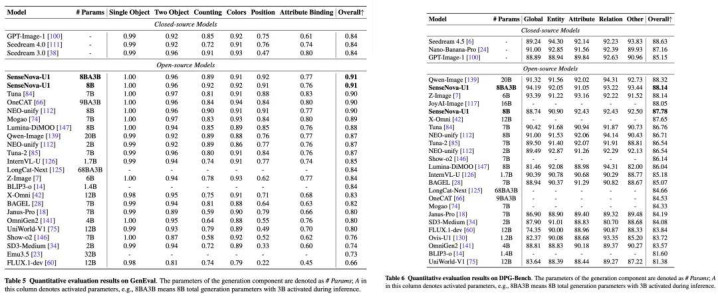
笔墨渲染持久是图像生成模子的软肋,多谈话混排更是难中之难。SenseNova U1 在这一领域赢得了突破性成绩:在 LongText-Bench 中,8B-MoT 英文和汉文得分分辩达到 0.979 和 0.962;CVTG-2K(多区域复短文字)最好平均词汇准确率 0.940,位列开源第一;TIIF-Bench 举座得分 89.74,为系数对比喻法最高。在中英文长文本与多区域笔墨渲染上达到开源 SOTA,发奋治理中英文混排、长文本排版等商用痛点。
在知识驱动图像生成基准 WISE(评测文化、时期、空间、生物、物理、化学等领域的寰球知识利用智商)上,启用 CoT 后 A3B-MoT 以 0.81 的举座得分达到系数对比喻法最好,与 GPT-Image-1(0.80)持平,远超无数开源模子 —— 原生结伙架构不仅营救高质料生成,还能将知识纠合鬈曲为更准确的视觉输出。
推广智商:复杂信息图、交错生成与协同效应一展无余
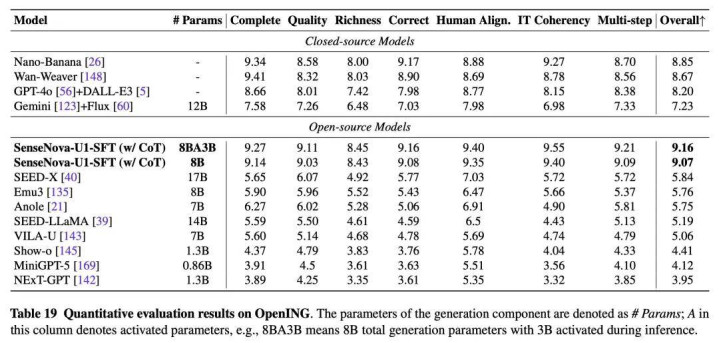
在计算图文交错生成的 openING 测试中,A3B-MoT 联结 CoT 以 9.16 的举座得分超越 Nano Banana(8.85)、Wan-Weaver(8.67)和 GPT-4o+DALL-E3(8.20),凭借更强的内容好意思满性、图像质料、图文连贯性和跨要津逻辑一致性,在长序列、复杂情境任务中证实隆起。
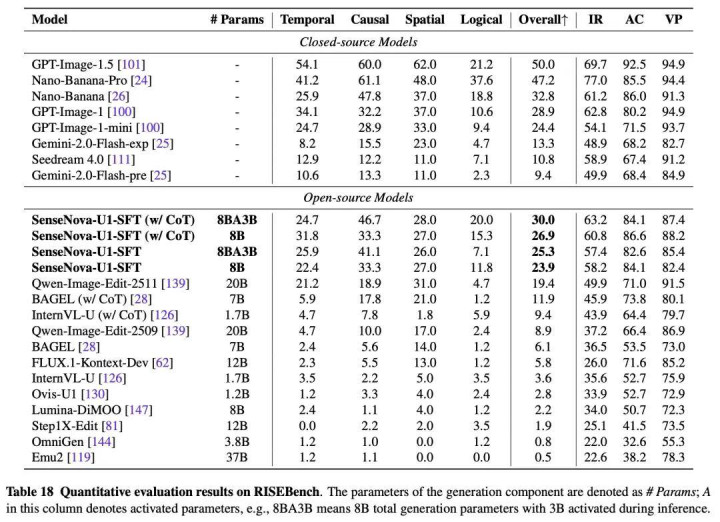
在纠合与生成协同的 RealUnify 基准(考验纠合增强生成 UEG 和生成增强纠合 GEU 两个场所)上,8B-MoT 举座平均得分 52.4,最初系数开源竞品(BAGEL 为 42.9、Ovis-U1 为 35.4),解释 SenseNova U1 能在复杂结伙任务中真确整合纠合与生成智商,而不是陋劣将两种智商放在合并骨干中。
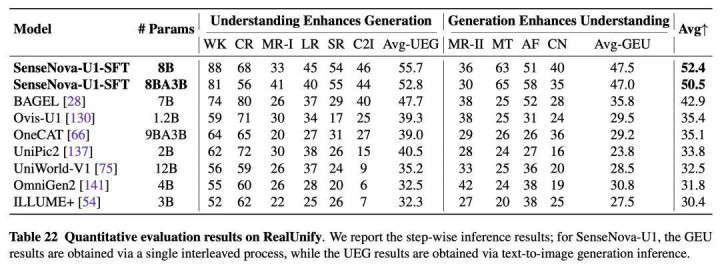
交易视觉内容基准 BizGenEval 中,SenseNova U1 在布局、属性、笔墨渲染和知识准确性多个维度均显赫最初主流开源模子,原生结伙架构在高复杂度专科视觉内容生成上展现出显赫后劲。
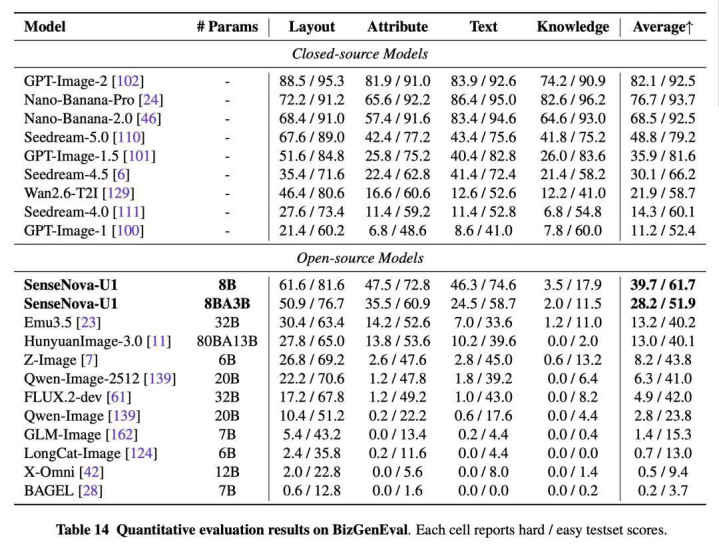
剪辑智商相似隆起,模子在 GEdit-Bench(7.47/7.32)与 ImgEdit(3.90/3.91)等主流榜单上证实持重,全面掩饰了物体添加、局部替换、作风蜕变、配景变更等常见操作。
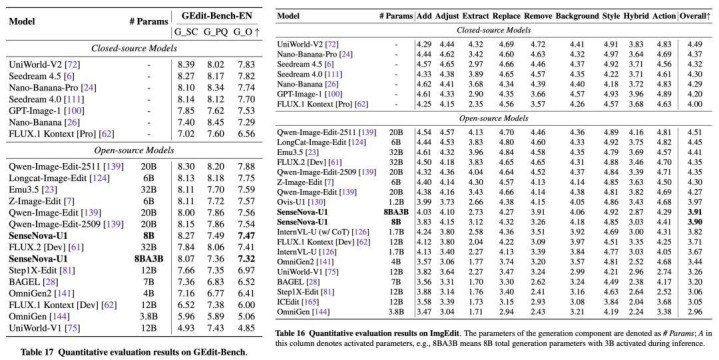
值得一提的是推理驱动剪辑 —— 模子并不是盲目修图,笔墨渲染、因果、空间和逻辑等方面均需先纠合再修改。RISEBench 测试中,A3B-MoT 在开启 CoT 后以 30.0 的开源最优得分,远超 BAGEL(6.1)和 FLUX.1-Kontext-Dev(5.8),标明 SenseNova U1 的上风不仅在于实施剪辑,更在于剪辑前所需的纠合与推贤惠商。
一个个基准成绩的突破,是对 SenseNova U1 代表的「原生结伙」范式可行性的有劲自证。
结语
SenseNova U1 的证实自然亮眼,但比喻针更值得关爱的,是它所指向的工夫旅途。
多模态正在从畴昔依赖模块拼接、徐徐对王人的工程念念路,转向更一体化的原生建模。智商不靠单纯拼接而来,开动「长在一齐」。图像停战话不仅仅放在合并个系统里使用,更在合并条链路中被协同纠合与生成。畴昔多模态主要治理的是「能不可用」的问题,刻下修起的是「能不可更接近东谈主类的使用情势」。
在原生结伙架构缓缓老练的配景下,「以小搏大」将不再是偶发步地,而是模子假想形而上学转变带来的势必扫尾。消融实验还是标明,NEO-Unify 在数据推广后果上明显优于同类方法 —— 以更少的熟习 token 竣事更高的性能,这意味着跟着数据领域进一步扩大,这一架构的上风还将连续放大。
下一个值得关爱的问题欧宝app(中国),是原生结伙范式在视频、音频乃至具身动作等更多模态上的推广鸿沟 —— 工夫敷陈中已表现了 VLA(视觉 - 谈话 - 动作)和寰球建模(WM)的初步实验,场所空匮可见。从这个角度来看,以 NEO-unify 为代表的原生结伙架构探索,从头界说了多模态模子该若何被构建、以及最终会走向那处。